
In 1879, the Gould & Curry mine in Nevada ran on Corliss steam engines that hit 97% efficiency. The electric motors being tried nearby managed about 60%. Within a decade every steam mine was gone.
That is the cleanest way to think about software right now. Electricity did not win because it was a better steam engine. It won because it made the engine disappear from the architecture of the factory. The belts, shafts, engine houses, and entire coordination system around power delivery did not get modernized so much as vanish from the problem entirely. Once power could be routed anywhere, factories stopped being organized around the machine that drove them and started being organized around the work.
Software is reaching the same point. The thing everyone is trying to make better is about to become the thing nobody organizes around. Code is becoming an input, and when an input collapses in price the value does not stay with the producer of the input. Carnegie did not win steel by finding better iron ore. Rockefeller did not win oil by drilling better wells. They won by owning the system that turned cheap inputs into reliable output at scale.
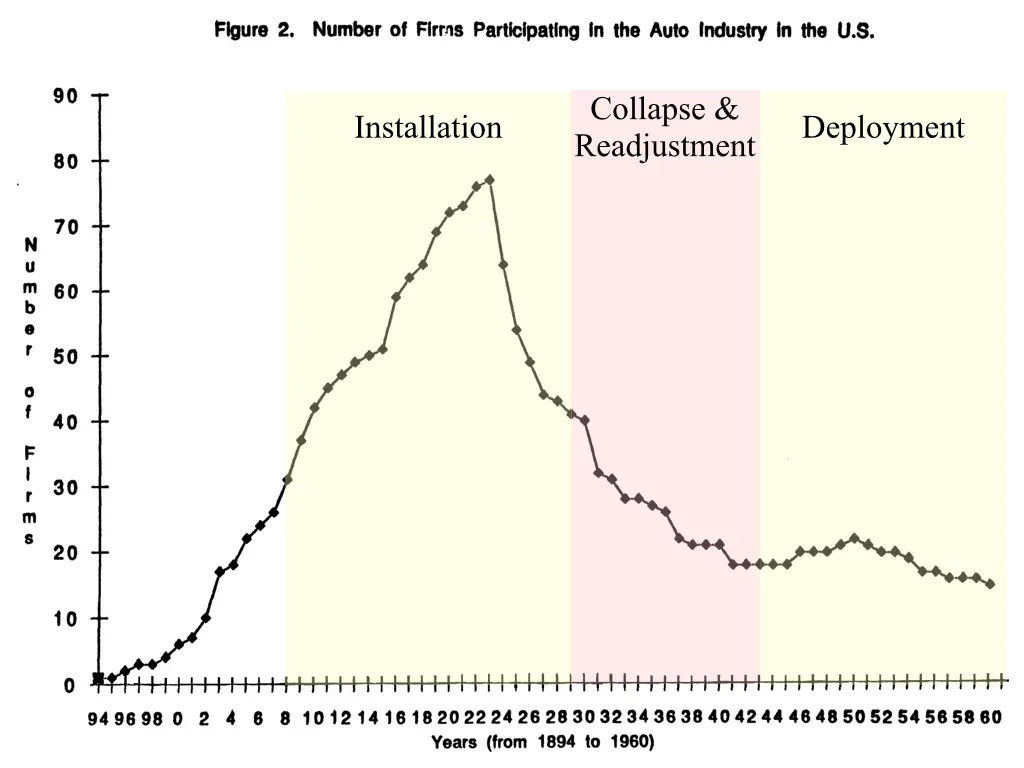
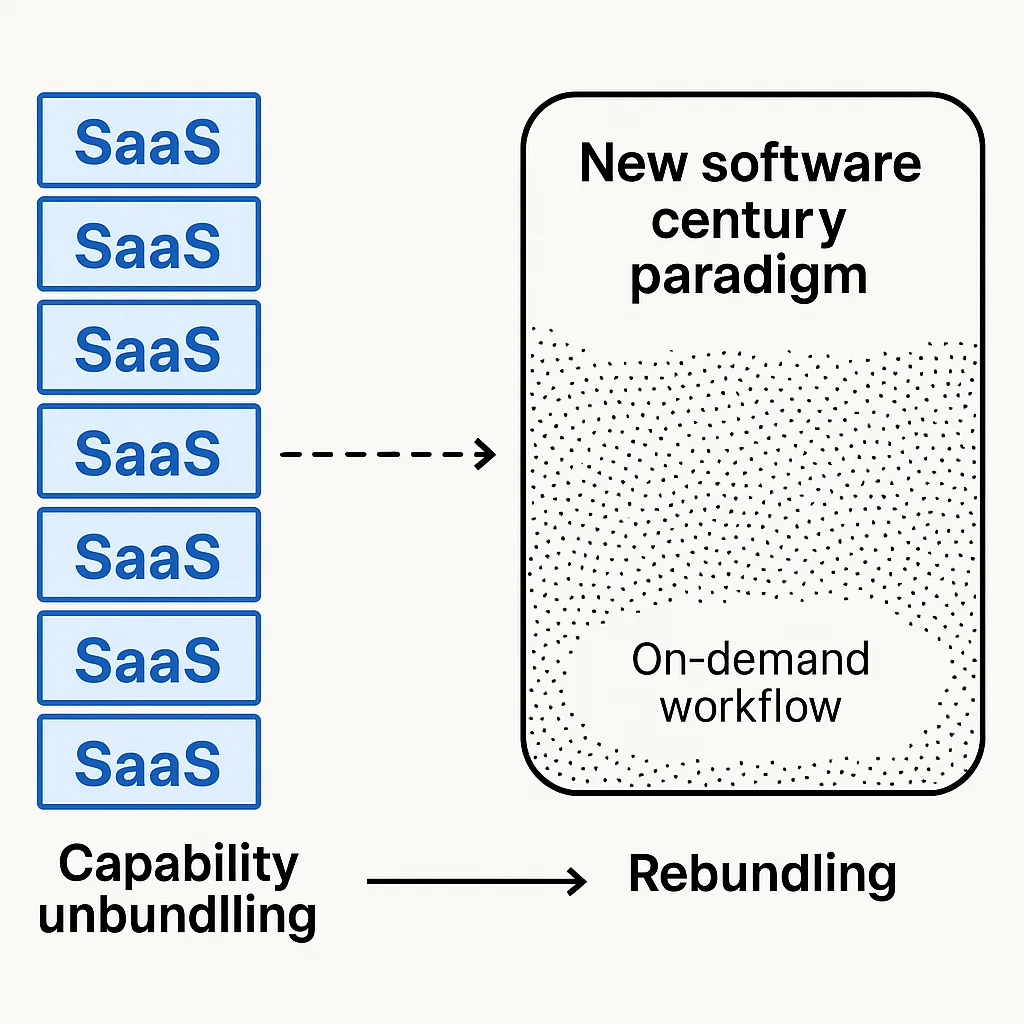
The software century is not the century where every company buys more SaaS. It is the century where software stops being scarce enough to sell in the same way. SaaS was never just a product category. It was a financing model for software that was too expensive for most companies to build themselves. Salesforce exists because building a CRM used to cost millions. Jira exists because coordinating the people who write code is its own operational tax. The whole SaaS economy is downstream of the fact that software was expensive to produce, expensive to maintain, and hard to customize.
If that changes, the category starts to unwind. Not all at once, and not because every employee suddenly becomes an engineer, but because the default assumption flips. The question stops being "what software should we buy?" and becomes "why is this process still running on someone else's frozen abstraction?"
The cost curve
OpenAI's SWE-Lancer benchmark is interesting because it maps model performance to actual freelance software tasks from Upwork instead of another synthetic coding exam. The benchmark is still early, and frontier models still fail a lot of real work, but the economic framing is the part that matters. In my own testing, a job worth $250 on Upwork ran for $3.75 on GPT-4o. That is a 66x markdown before you even account for the fact that the operator can run many attempts in parallel.
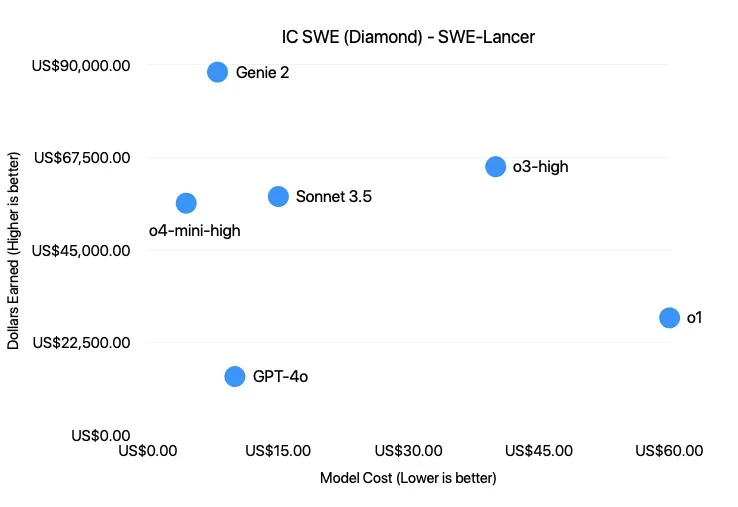
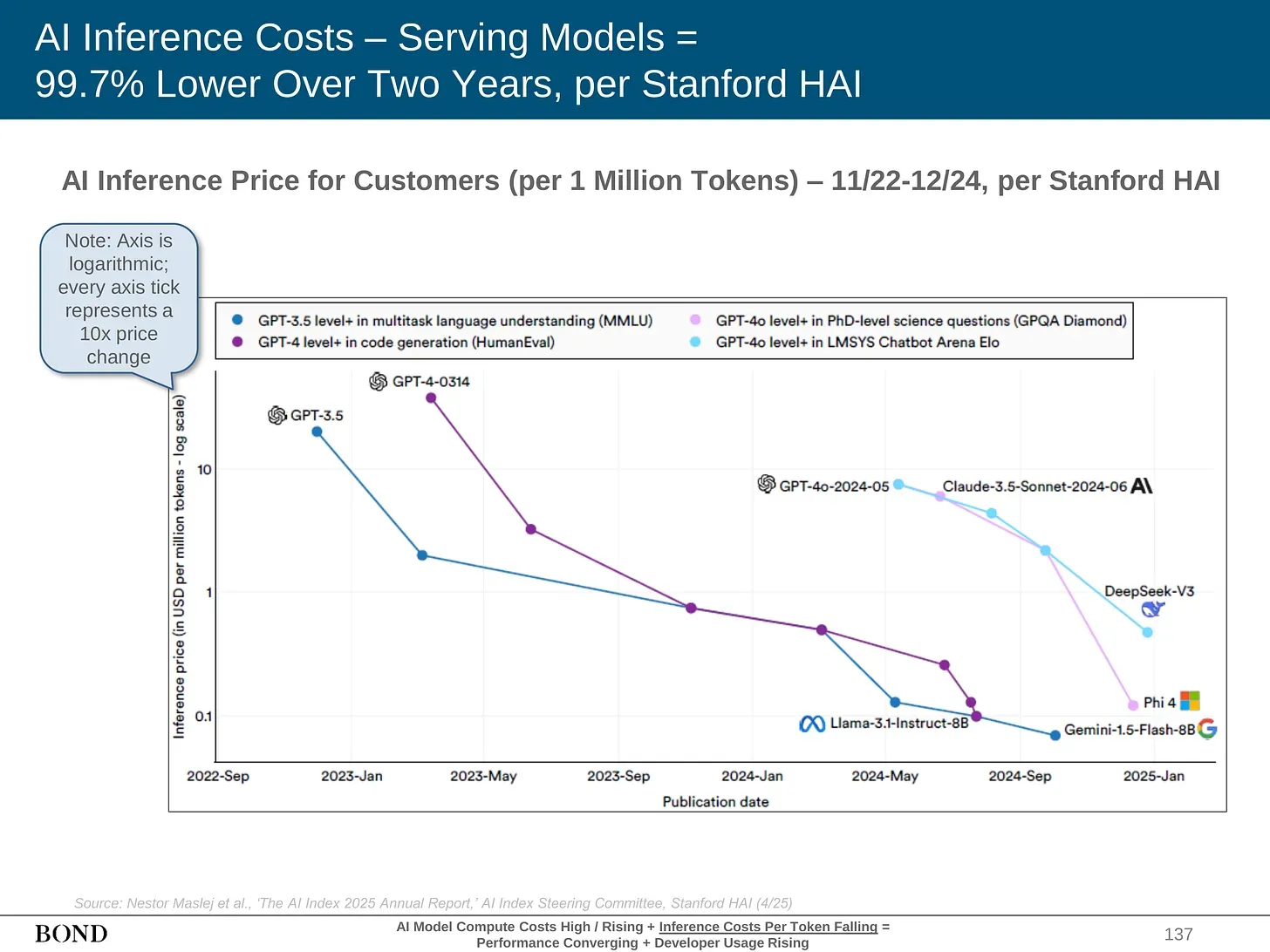
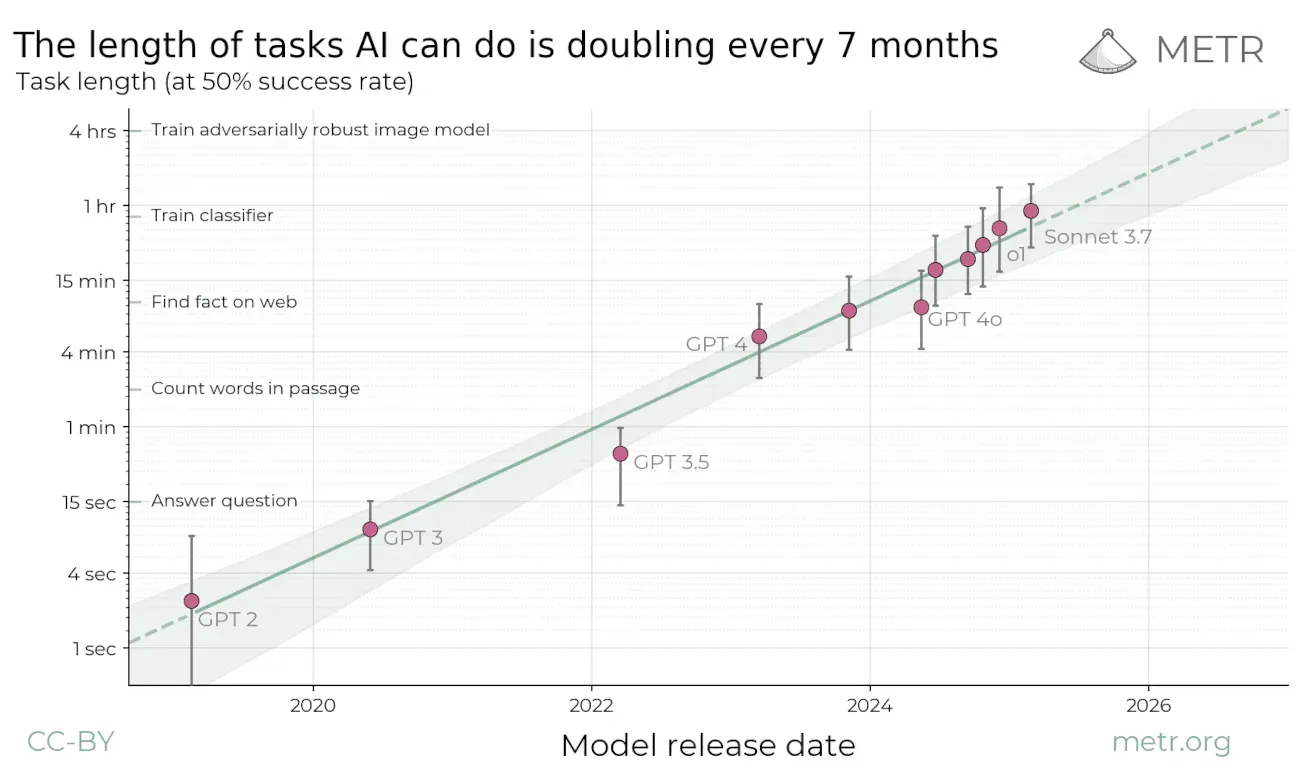
This is the part people underwrite incorrectly. The current arbitrage exists partly because the labs are subsidizing inference to win market share. Token prices are not clean reflections of long-term cost. But even if the subsidy goes away, the structural trend is still obvious. Stanford HAI's 2025 AI Index says the cost of running a GPT-3.5-level model fell more than 280x between November 2022 and October 2024. METR estimates that the length of tasks AI agents can complete with 50% reliability has doubled roughly every seven months over the last six years.
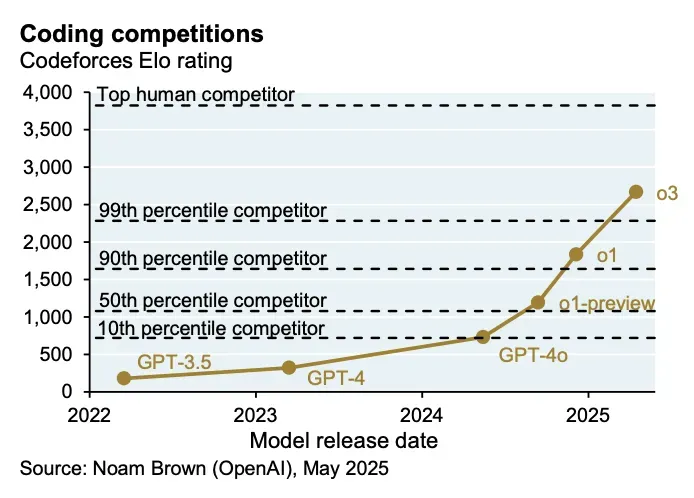
The point is not that models magically replace engineers tomorrow. That is the boring argument, and it usually collapses the moment you ask who specifies the work, verifies the output, handles deployment, takes responsibility, or owns the customer. The better argument is that software creation is moving from capital expenditure to operating input. Once that happens, the money moves to whoever can turn raw output into something verified and deployed.
The graveyard
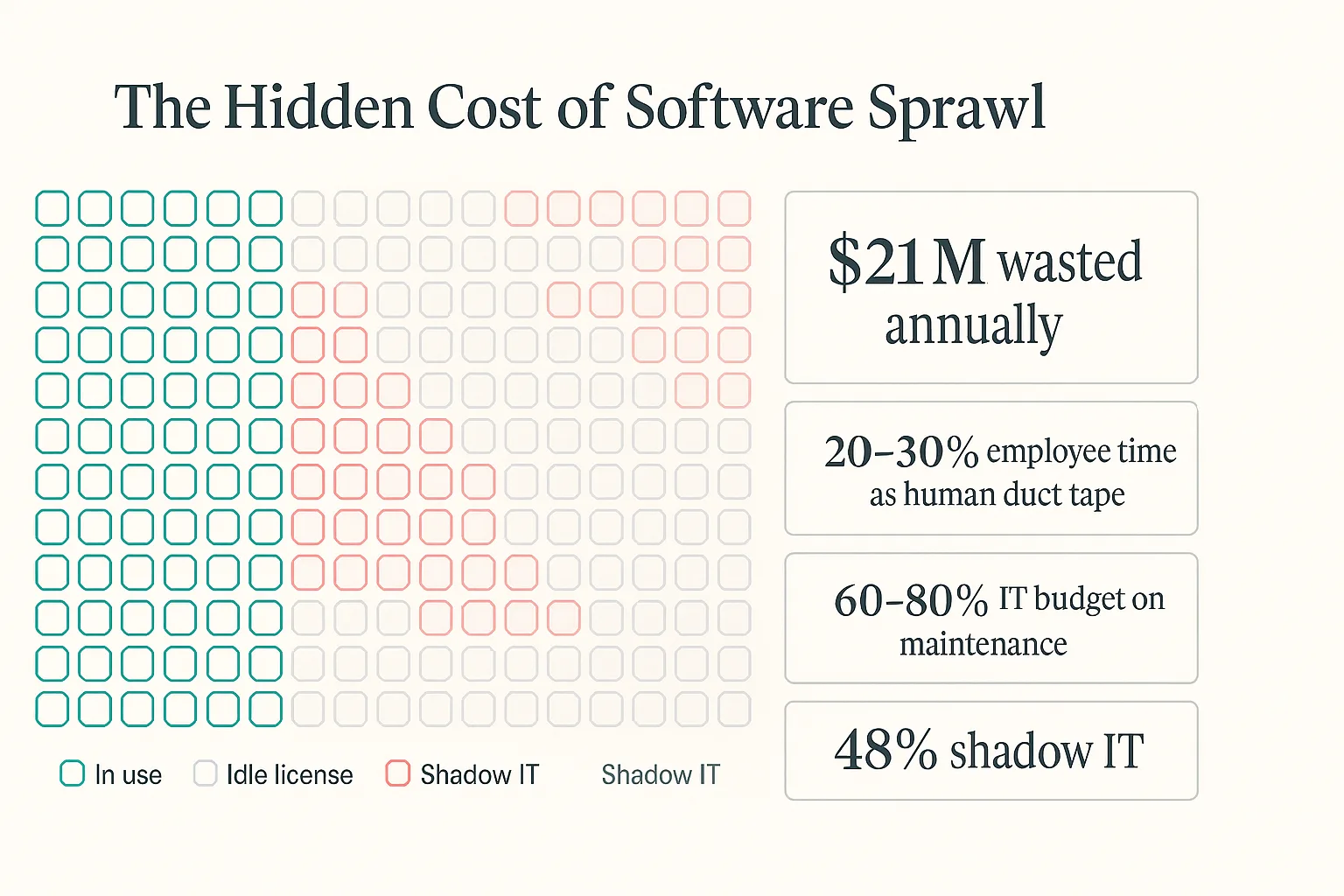
The DOGE software-license audits were a useful example, even if the politics around them make everyone worse at reading the signal. Wired reported that the GSA had 37,000 WinZip licenses for about 13,000 employees. Maybe some of that was per-device licensing. Maybe some of it was normal government procurement weirdness. The exact explanation matters less than the shape of the problem, because every large organization has some version of this sitting inside it.
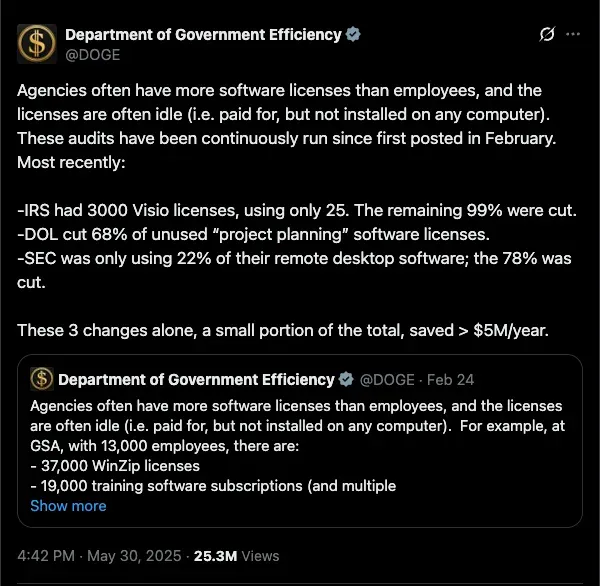
The better reading is that this is the natural end state of buying software one slice at a time for twenty years. Every team buys one tool because it solves one local problem. Every vendor extracts rent for one narrow workflow. Eventually the company has a stack that nobody designed, nobody fully understands, and everybody has to route their day through. The software did not fail because it stopped running. It failed because the organization started working for the software.
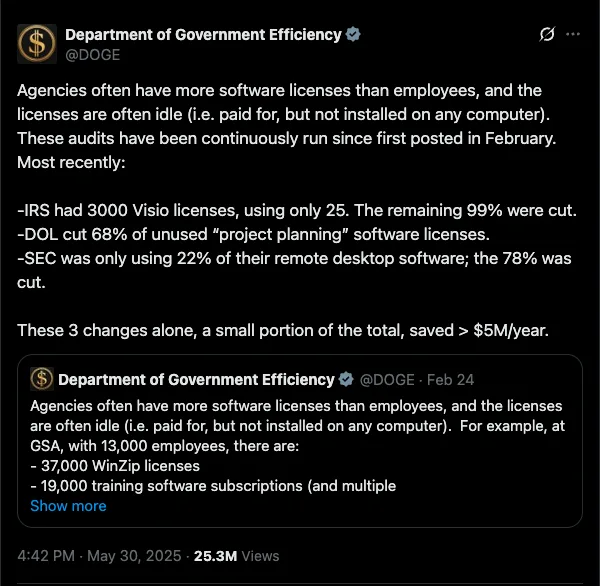
The real DOGE lesson is that modernization became easy once permission existed. When people are given permission to start over, they usually do not want to carefully retrofit a twenty-five-year-old system. They open Cursor, use Claude, wire together the primitives, and generate a new version of the workflow. The old stack persists because the political and operational cost of replacing it has been higher than the cost of the software itself. Once generation gets cheap enough, the decision becomes the expensive part.
Intent
The other part of software that is getting cheaper is control flow. Every application built in the last thirty years is basically someone's hardcoded guess about what the user might want to do next. The product is a set of paths. The interface is a map of allowed moves. The business logic is if/else statements wrapped in permissions, buttons, forms, integrations, and dashboards.
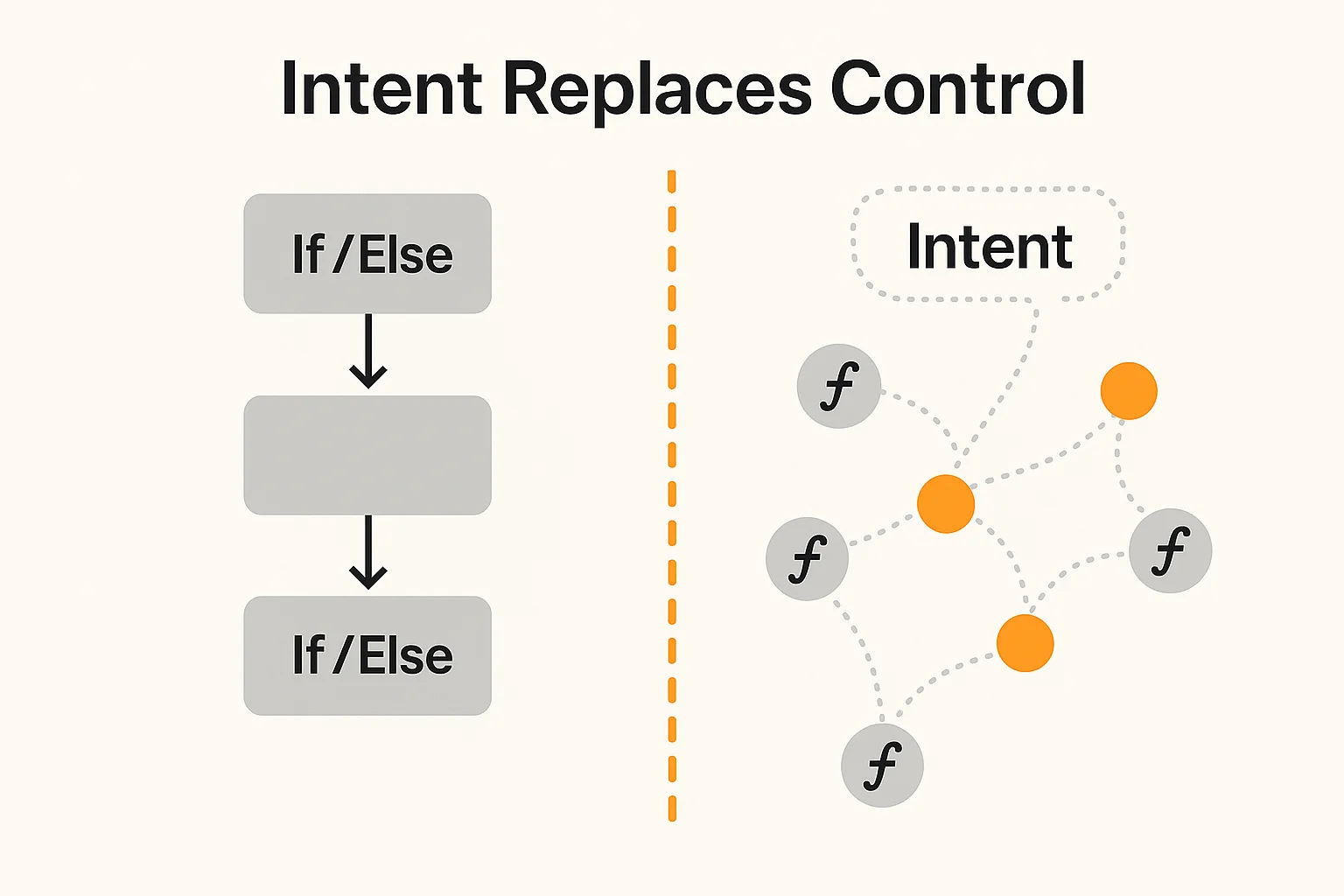
This was necessary when software was expensive. If a company could only afford to build one workflow, the workflow had to be fixed in advance. Users learned the product because the product could not learn the user. That assumption is starting to break.
The gap between GPT-3.5 and ChatGPT was not just the model. It was the application layer around the model. The same underlying intelligence became useful when it had memory, tools, a conversational loop, and a way to translate intent into action. That pattern is now spreading into normal software. The user states intent. The system works out the path. The interface becomes less like a fixed dashboard and more like a temporary surface generated for the job.
Prompting is harder than coding in a strange way because code has a compiler and prompts do not. With code, wrongness has a shape. With prompts, wrongness is often plausible and contextual, often discovered late. That is why the winning layer is not a thin chat box on top of a legacy app. It is the runtime around the model: evals, permissions, tools, state, audit logs, and deployment rails. In the 1890s, factory engineers bolted electric motors onto steam-powered lathes and wondered why nothing improved. The same thing happens when an AI feature is bolted onto old SaaS. The old stack does not get upgraded, it gets bypassed, and the company that owns the old stack is usually the last to notice.
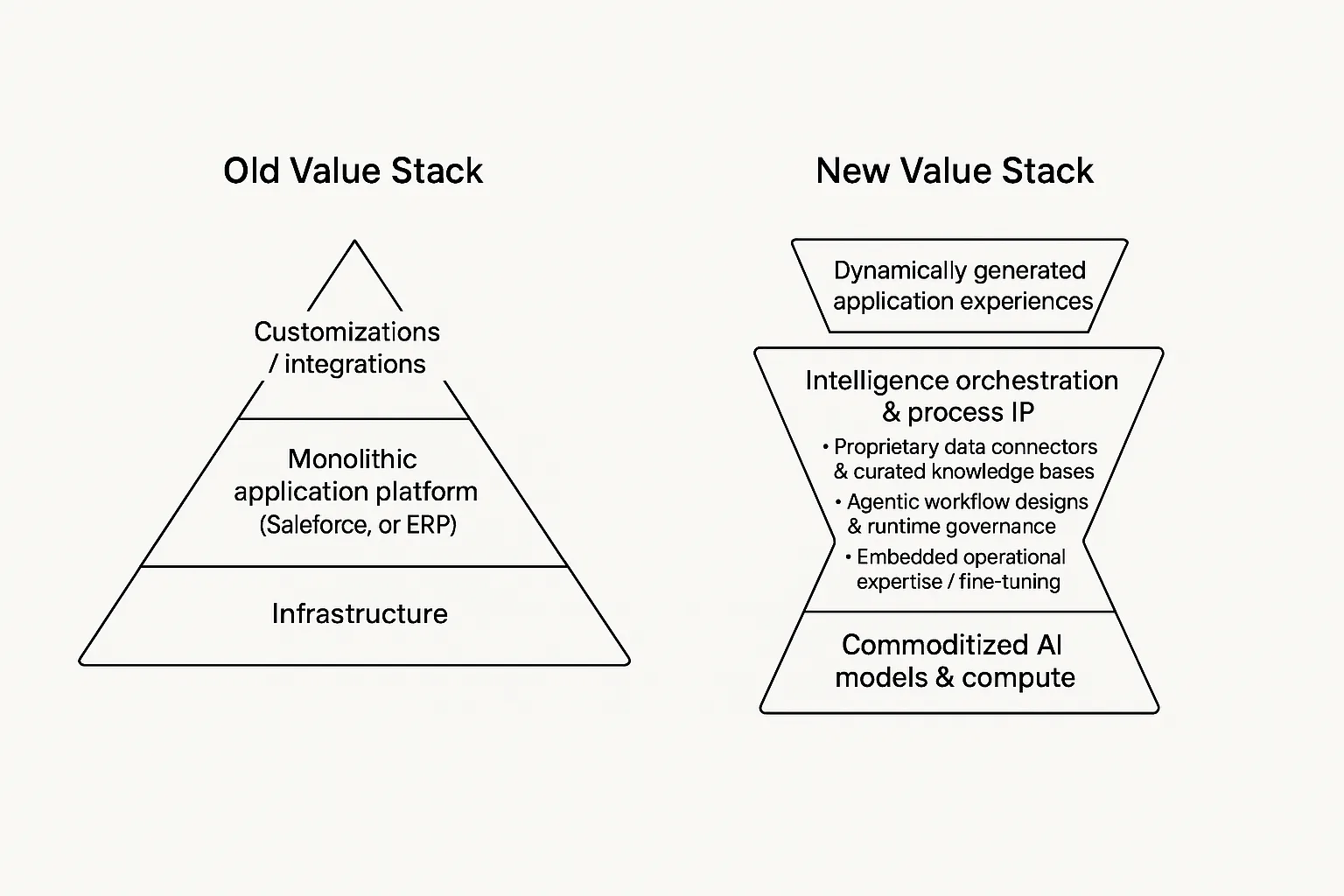
The factory
Tokens are the crude oil of this decade, and wrappers are alloys. They are useful, they can be valuable for a while, and some will become real companies, but they are not the deepest part of the stack. The missing piece is the refinery: the process that turns raw generation into software that can actually run inside a company.
Raw generation is not the hard part forever. The hard part is everything around it: specification, evals, integrations, security, permissions, deployment, monitoring, and the boring proof that the output did the thing it was supposed to do. Enterprises do not buy code so much as responsibility: something that works with their systems, survives audits, maps to their workflows, and has somebody accountable when it breaks.

The shape of the winner probably does not look like a normal SaaS company at first. It looks more like a services firm that industrializes itself until it is not really a services firm anymore. Oracle started with high-touch database work for the CIA before it became a product company. Palantir spent years with forward-deployed engineers inside customer sites before Foundry looked like a platform. Scale AI started with human labeling operations before the labeling workflow became infrastructure. The pattern is not glamorous, but it is consistent. A manual service becomes repeatable, the repeatable parts become tools, and the tools become the product.
The software version of this is just-in-time software. Most software is stale the moment it ships because it encodes the business as it existed during the build cycle. Then the world changes, the process changes, the customer changes, and the company keeps paying maintenance on a version of reality that no longer exists. If generation becomes cheap enough, there is no reason every workflow needs to live inside a permanent app. The durable primitives are things like data, identity, payments, compliance, and audit. Everything above that can become more temporary, more generated, and more specific to the task.
Owning the railroad
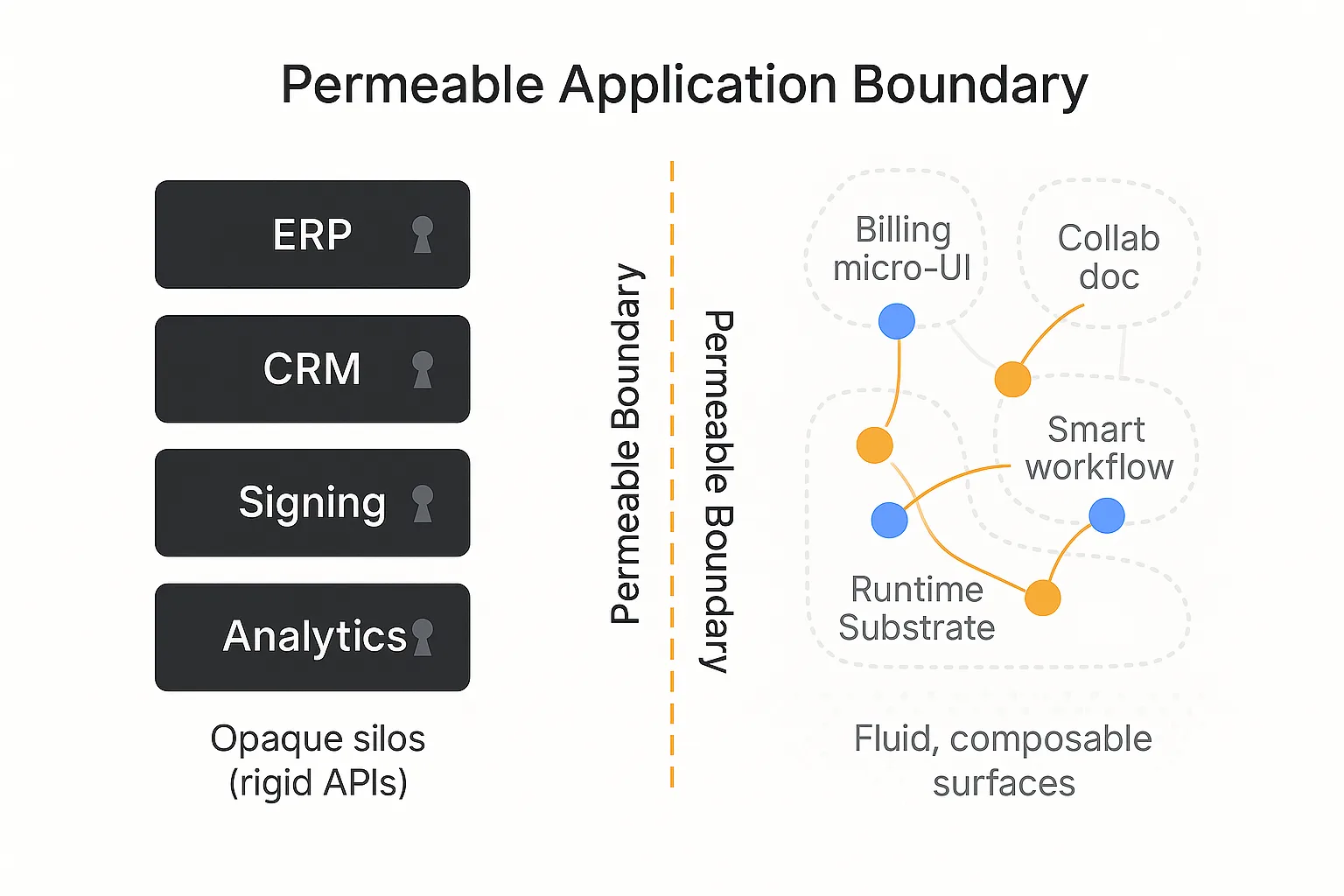
Rockefeller's line about oil is the one that still matters: finding it was not the hard part, getting it to market was. His real control came from pipelines as much as wells. The software version is the same. The model may be the product, but distribution is still the moat. In a world where models keep converging, the winning company is not necessarily the one with the cleverest wrapper or even the best model for a moment in time. It is the one that controls the path from intent to deployed work.
That means owning the rails: deployment, compliance, integration, audit, and feedback. Every deployed workflow should make the next one cheaper. Every customer should create process data, edge cases, evals, connectors, and templates. Every run should leave a trace that improves the factory. This is why the interesting AI companies are not just selling output. They are trying to own environments, trajectories, and distribution.
Most of what enterprises pay for is not really software anyway. It is work performed through software: filing a Suspicious Activity Report, reissuing a certificate of insurance, submitting a prior authorization, pulling SOC 2 evidence, reconciling invoices, checking sanctions lists, and updating customer records across five systems that should have been one system. These are narrow, regulated, must-do tasks that have historically gone to BPOs, offshore teams, or SaaS tools because building a custom automation for each one was more expensive than hiring people to suffer through the workflow.
When that inequality flips, the category moves. Software stops being the thing you buy so humans can do the work. Software becomes the thing generated around the work itself.
The software century
The mistake is to think this is mostly about coding agents. Coding agents are just the first visible symptom because developers live closest to the production function. The bigger shift is that software itself becomes a material. You describe the thing you want done, the system generates the workflow, the workflow runs against durable company primitives, and the output is verified. Sometimes a human stays in the loop. Sometimes the human only approves exceptions. Over time the company stops accumulating apps and starts accumulating capability.
This will probably look messy for a while. The first electric factories looked like steam factories with motors attached. The first AI-native companies look like SaaS companies with chat boxes attached. That is how every transition starts, because people copy the form of the old system before they understand the new constraint.
The constraint is not code anymore. The constraint is deciding what should exist, proving that it works, and distributing it into the places where work actually happens. The engine becomes cheap, then invisible, then assumed. What remains is the factory.
Sources
- OpenAI, SWE-Lancer benchmark - https://openai.com/index/swe-lancer/
- Stanford HAI, 2025 AI Index Report - https://hai.stanford.edu/ai-index/2025-ai-index-report
- METR, Measuring AI Ability to Complete Long Tasks - https://metr.org/blog/2025-03-19-measuring-ai-ability-to-complete-long-tasks/
- Wired, DOGE's Misplaced War on Software Licenses - https://www.wired.com/story/doge-software-license-cancel-federal-budget/