
Most AI startups today build on top of the lab APIs. That works for now. But if history rhymes, every serious AI company will eventually train its own models — even the wrappers. Why? Because the barrier to doing so is collapsing. Distillation, fine-tuning, and post-training get easier every month. By the time ASI-level players are soaking up all the capital and talent, the only way to stay relevant will be to own your own models.
How We Got Here
In 2019, OpenAI released GPT-2 in staged checkpoints (by size) due to safety concerns. After GPT-3, others—notably Cohere and Primer—began training and releasing their own models. Midjourney and Stable Diffusion followed, building on diffusion research. Commercialization ramped in late 2022–early 2023.
By 2024, anyone with a rack of GPUs could spin up a training run. By 2025, DeepSeek distilled a frontier model for ~$6M that matched OpenAI’s o1-level reasoning—four months after o1 was announced and two months after it shipped.
The point: the models behind the APIs aren’t far from what anyone else can train.

Reproducing Models Isn’t Magic
The ingredients are simple: data, compute, and architecture.
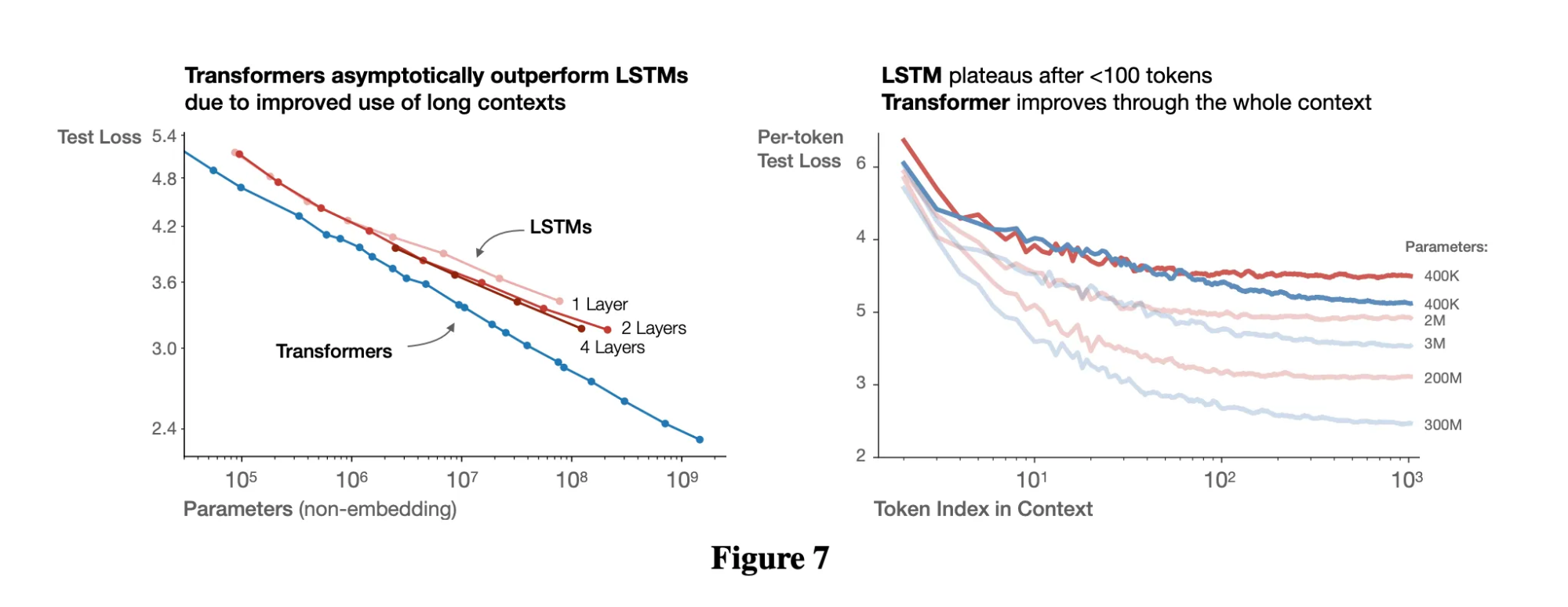
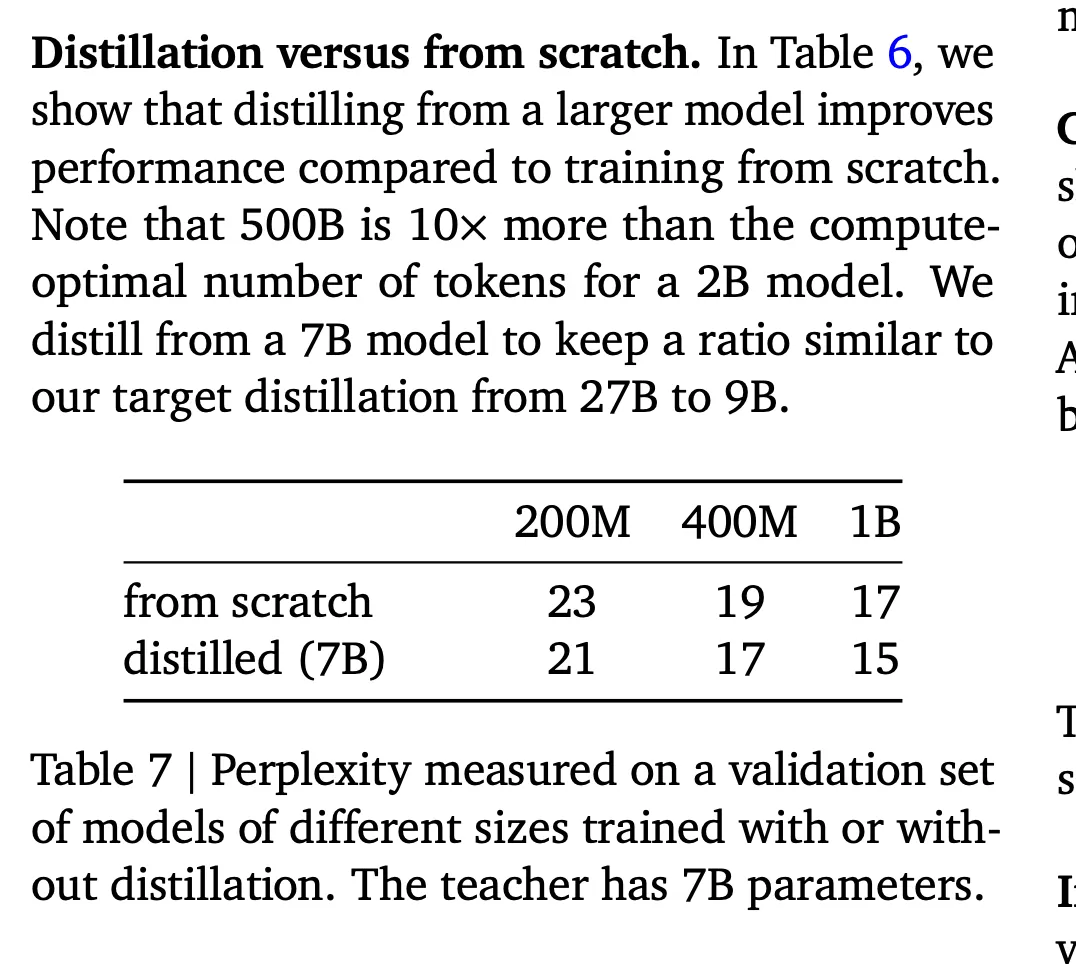
Transformers have already proven themselves to asymptotically outperform LSTMs. With open knowledge of pre-training, post-training, and inference, there’s little that can’t be replicated or simply vibe coded with Claude and Codex. Compute is just a skill issue on finding capital. And procuring data can be distilled, Phi-4 and Gemma as a sample of the symptom showed in a recent paper that a distilled 1B can match a 7B trained from scratch.
Remember how software felt “hard” in the 2000s? You needed servers, versioning, CDs, and competent engineers. Yet, once someone found a new modality, they could dominate commerce (Amazon) or search (Google). Training today feels the same. Hard, but not impossibly hard.
The wedge is not new architectures. It's data efficiency and reinforcement learning. Diffusion may yet show some promise, but efficiency is a factor due to how limited we are on compute and data.
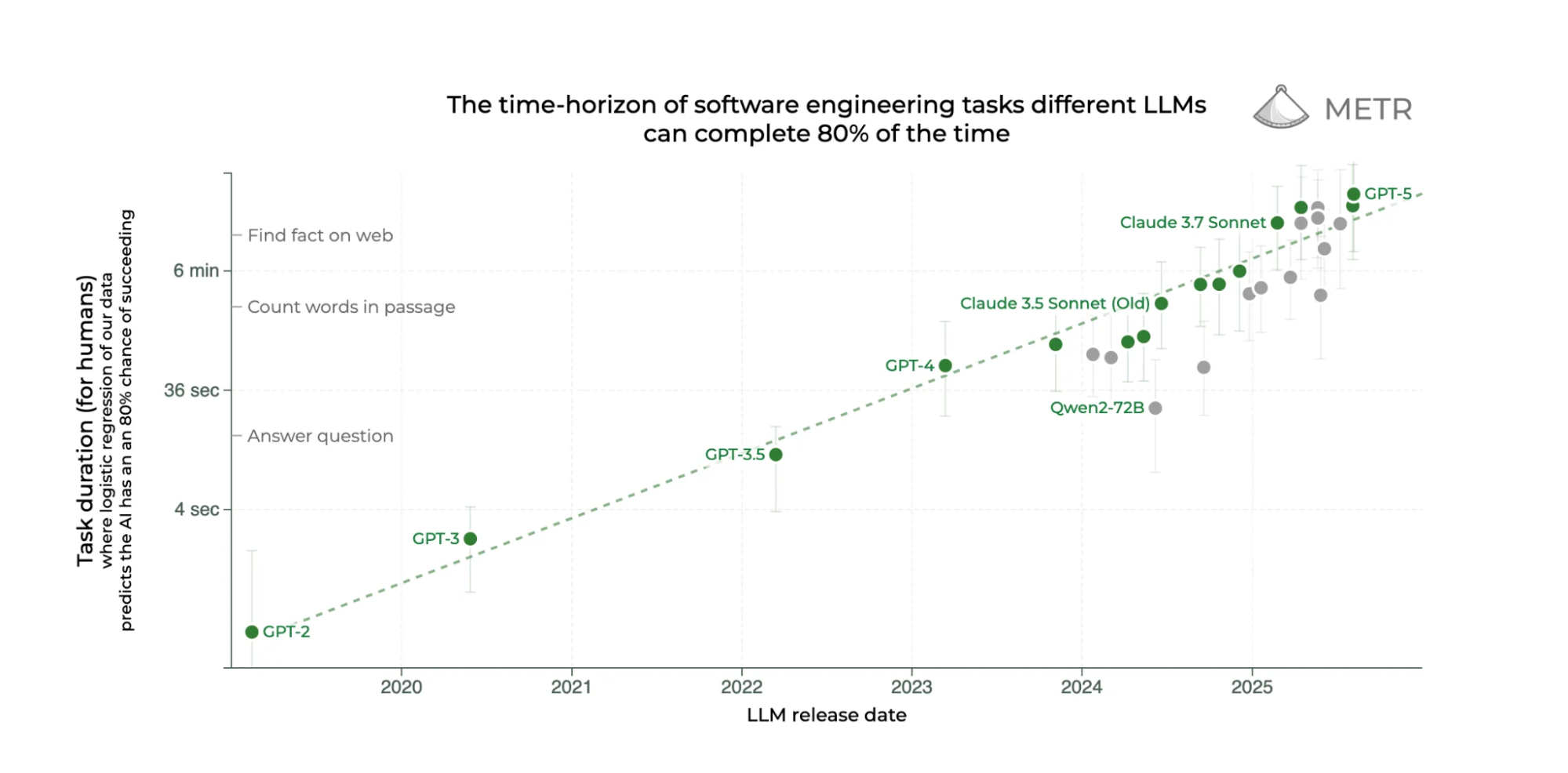
Economics
So why would an application company ever bother training?
Because once most programming tasks under 30 minutes are automated by the end of this year, software itself starts to look like another direct-to-consumer brand. Distribution is what (always) matters.
Cursor began as a wrapper on VSCode and GPT-4. Today, it also runs proprietary models. Officially for “Fast Apply” and features like that. But with billions of traces, Cursor could RL a model that handles hours of software engineering. At some point, the exact backend model stops mattering. What matters is that Cursor controls it.
The pattern is consistent:
- Start with an API wrapper to find PMF and collect data.
- Fine-tune small specialized models for specific features.
- Train your own models, using your data moat.
- Increase Total Factor Productivity per token input, i.e. how much value do you provide the user; to retain users. More on this below.
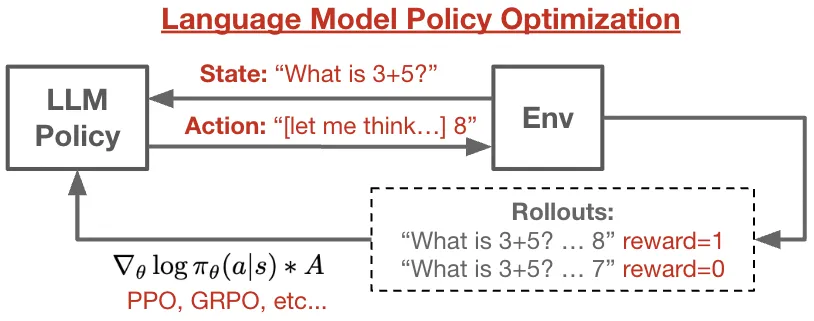
Your app effectively becomes the RL environment. Or you sell your valuable trajectories back to the labs.
Data Is the Bottleneck
OpenAI bought Statsig to capture the billions of trajectory replays they have in their “Session Replays” product that records everything users do on screen. Sutton and Silver called this the “Era of Experience” — the next frontier is data from agents interacting with their environment.
That’s why I believe computer use is a meaningful path to AGI. Every software interface becomes an environment and every set of actions becomes experience data. The professional world already spends most of its life in front of a computer. Think of the hours of unlabeled, unrecorded data we’re missing.
Once the model is the product, compounding input is experience. Whoever gathers the replays builds leverage.
Token Factor Productivity
I pay $200/month for Claude Pro. But the value I receive is worth five to six figures a year. So I almost receive $42 of value for every $1 spent. At that margin, the rational move is to train your own models.
We should start measuring metrics of productivity instead of usage:
- Tokens per unit of work.
- Economic value per token.
- Token Factor Productivity (TFP).
The TFP metric at its simplest:
TFP = (Economic Value of Output) / (Tokens Consumed)
Where:
- Economic Value of Output = the dollar value of the work produced by the model.
- Tokens Consumed = the number of tokens used in the process (input + output, or whichever scope you define).
Like Total Factor Productivity in economics, TFP measures how much value each token produces.
For my own use, I yield less than 1-10% of tokens generated into code merged in production. So at API pricing I pay (as an example) ~$2k/month for 1.7 billion tokens blended input/output between opus and sonnet with aggressive caching. ~$200 of which is actually valuable to me to which in theory I would pay $100k/yr for, so in practice I get $42 of value per $1 on tokens. And assuming inferencing is at-cost, Claude generates 42x in TFP for me! If I ran a Claude Code wrapper unless I was running inferencing too this would be impossible in the long term, I would much rather be in the position of Devin.
As AI diffuses across the economy this metric will increasingly become more popular. What is the price of a vibe coded RL environment considering the cost of input tokens and the price someone is willing to buy the final product? What is the price someone will pay to upskill and train physicians, residents, and students? What would you pay for the work of keeping your entire org SOX compliant?
The End
Models are no longer a function of intelligence but a factor of productivity. We should measure this in TFP, while also factoring in yield, inference pricing, etc.
We're watching software eat the world, and models start eating into labor. The companies that will survive will be those who can productively turn tokens into labor with the highest ROI.
Sources:
- Diffusion RL/efficiency discussion — https://arxiv.org/abs/2507.15857
- Economic value from automation — https://epoch.ai/gradient-updates/most-ai-value-will-come-from-broad-automation-not-from-r-d
- Time horizons across domains — https://metr.org/blog/2025-07-14-how-does-time-horizon-vary-across-domains/
- LMPO: Language Model Post-training with RL — https://github.com/kvfrans/lmpo
- AI model pricing and performance trends — https://artificialanalysis.ai/trends